email:
kosakaboat[at]gmail.com

|
I am currently a PhD student at The National Institute of Informatics, and The Graduate University for Advanced Studies, SOKENDAI, advised by Prof. Akihiro Sugimoto and sub-supervisor Prof. Pajdla Tomas. Norio completed an MSc in Mathematics at Birkbeck, University of London, with a thesis titled "Overview of Riemann surfaces." with the supervision of Prof. Ben Fairbairn. He also did an MSc in Machine Learning with Distinction at Royal Holloway University of London, focusing on the intersection of Reinforcement Learning and Robotics for his Master's Thesis, under the guidance of Prof. Chris Watkins. Research interests: Mathematics (Riemann surface, Hyperbolic geometry, and Algebric geometry) and Machine / Reinforcement Learning |
|
|
|
|
|

|
|
|
|
|
|
|
|
|
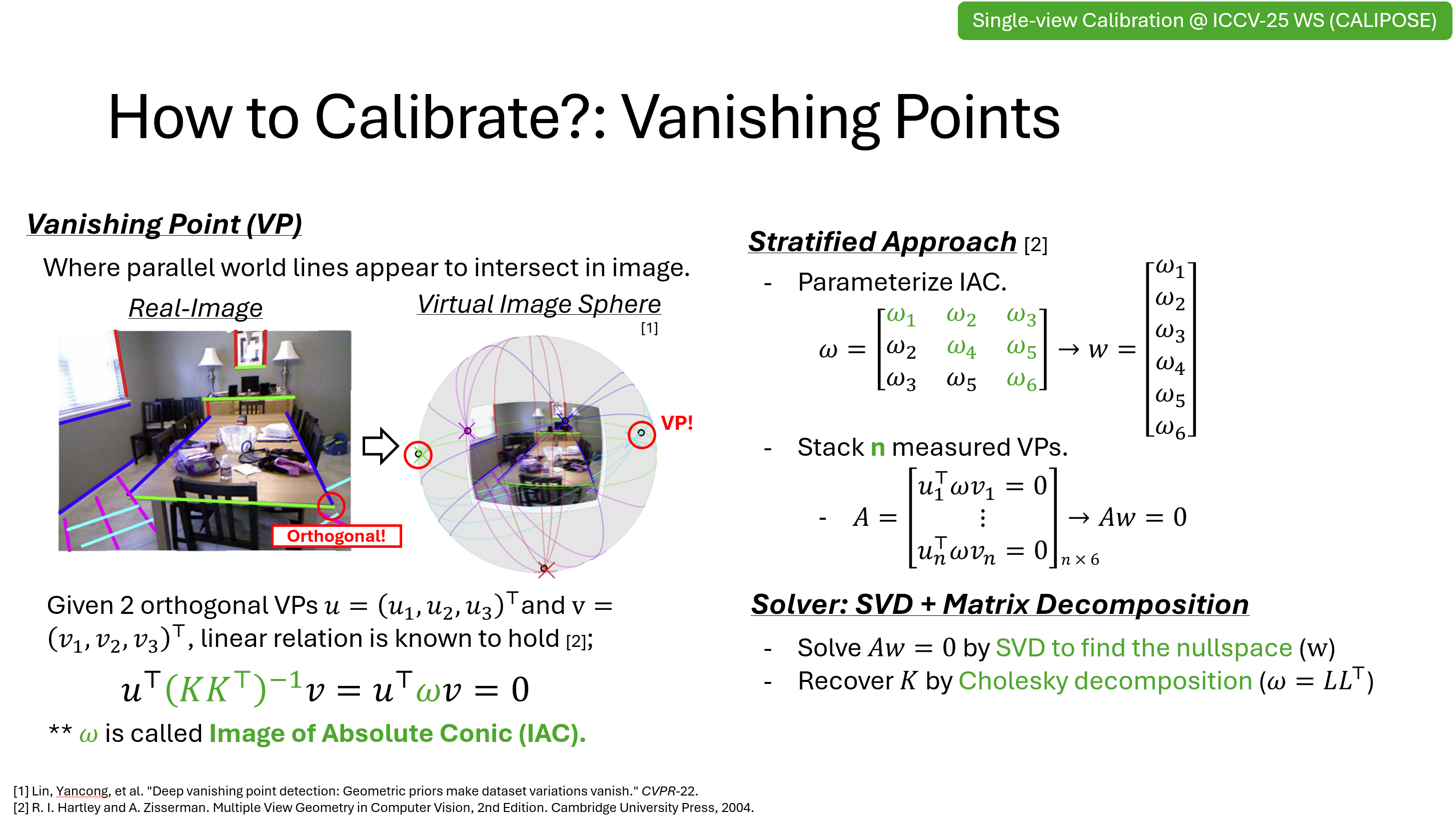
SummaryWe replace fragile stratified calibration with a direct polynomial solver using homotopy continuation, achieving robust intrinsics recovery from vanishing points (100% synthetic success; strong real-data performance) without any training. |
![[NEW]](./images/new.png)
|
|
|
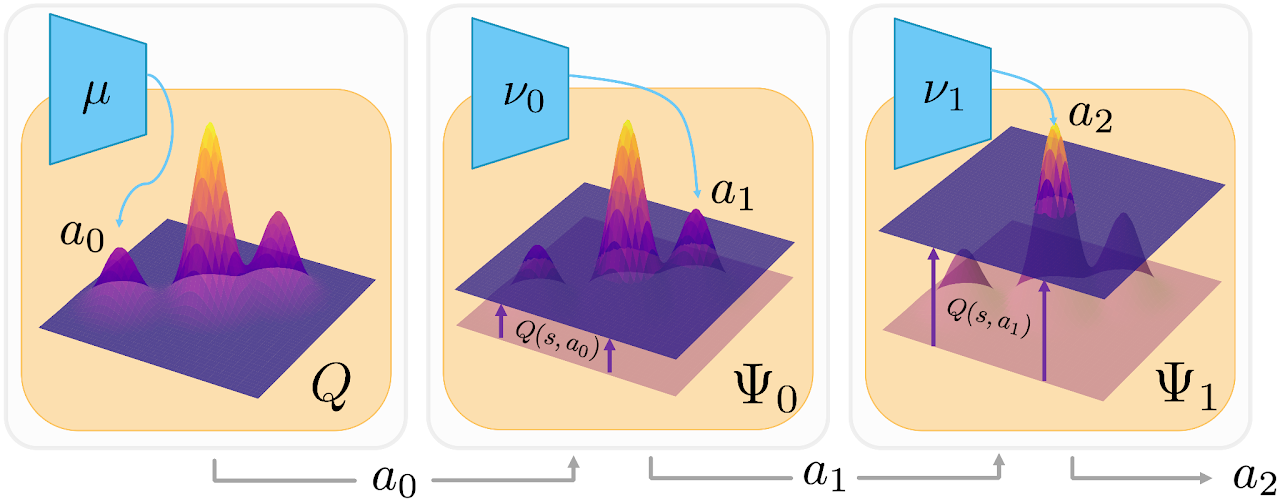
SummaryWe introduce SAVO, a successive-actor method that prunes low-value regions in complex Q-landscapes so TD3 avoids local optima, delivering higher returns and better sample efficiency across MuJoCo, Adroit, RecSim and gridworld. |

|
SummaryWe make critics evaluate the predicted afterstate (next state) rather than raw actions, simplifying value estimation; plugged into DDPG/SAC this yields faster, stabler learning on MuJoCo, PaintGym and RecSim. |
|
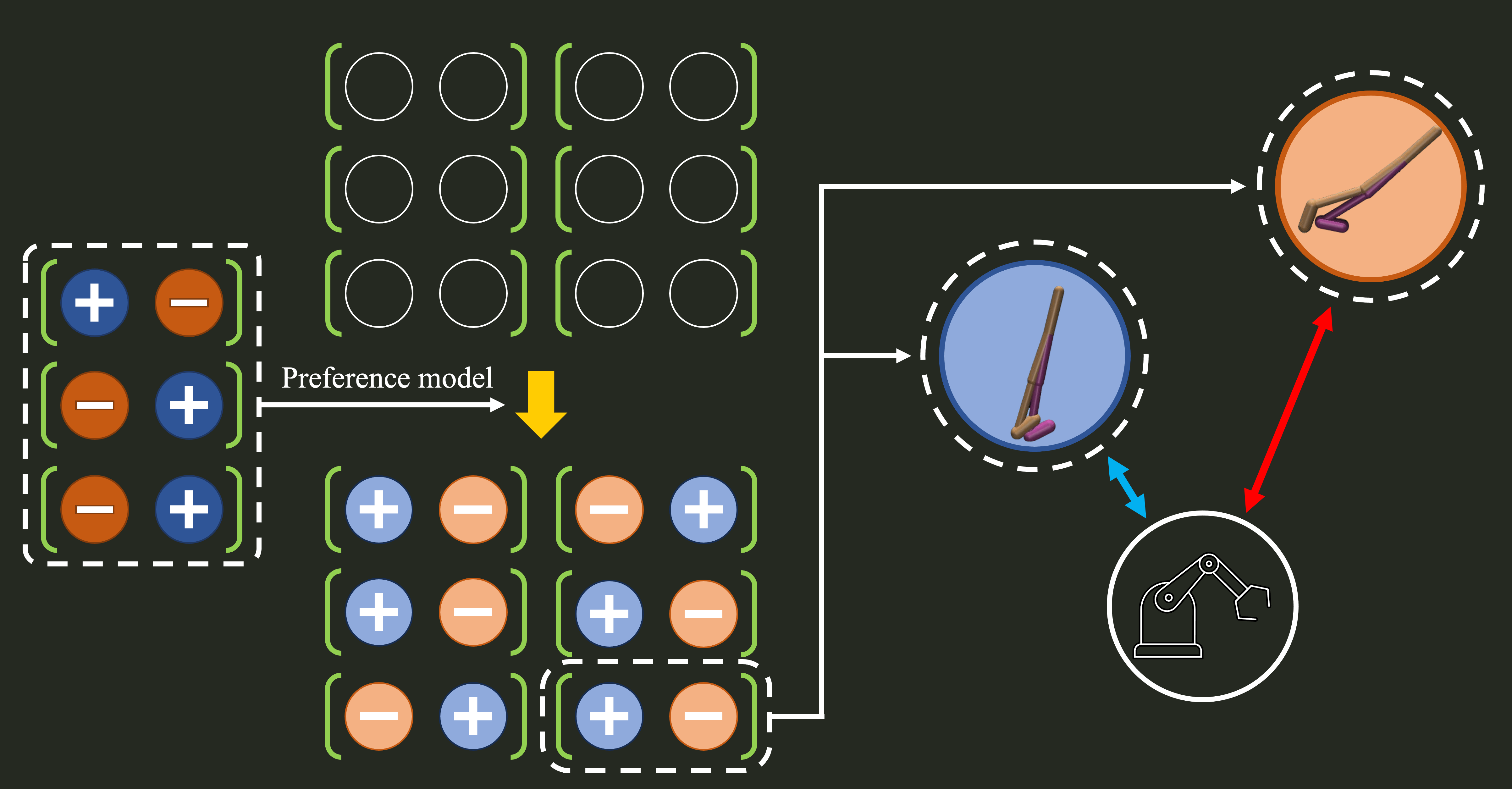
SummaryDPPO learns policies directly from preference labels (no reward model), improving robustness and efficiency on D4RL/Adroit/Kitchen and transferring to RLHF for LLMs. |

|
SummaryAGILE uses a graph-attention policy to model dependencies between available actions, boosting performance and generalisation in tool-use and recommender settings. |
|
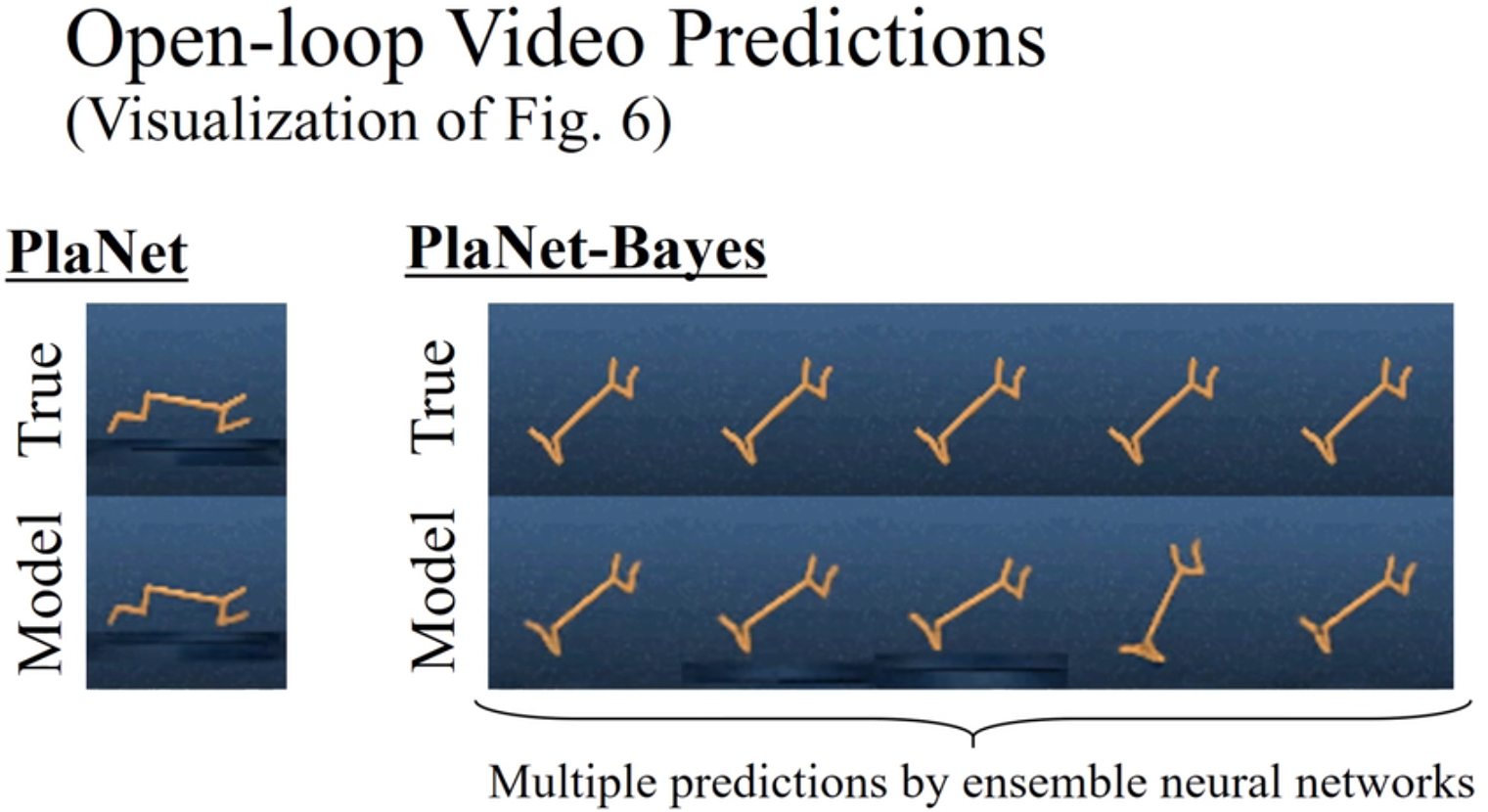
SummaryWe add Bayesian model and action uncertainty (ensembles + probabilistic MPC) to PlaNet, improving planning robustness and sample efficiency on DeepMind Control Suite. |
|
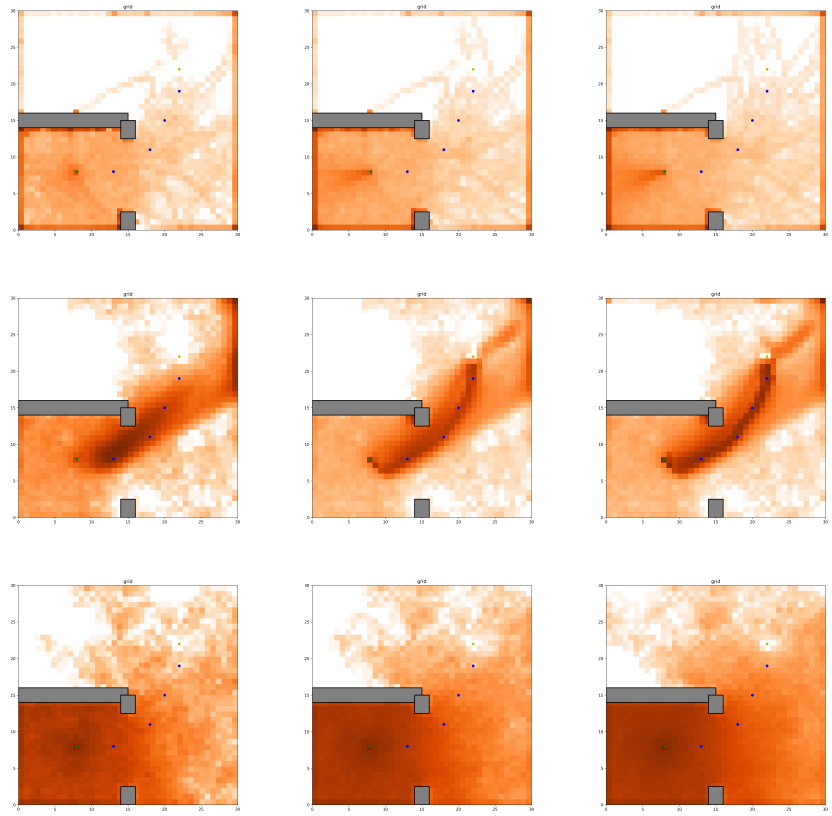
SummaryAn ablation-driven study of DDPG exploration (noise processes, BatchNorm, on/off-policy) vs SAC/GNN policies on MuJoCo, Centipede and gridworld, explaining when and why DDPG fails to explore. |

|
|

|
|
|
|
|
|
Template: this |